
Software Reliability is a field in software engineering rather than the sentiments about a software. We often see commercials claiming high reliability for a product either hardware or software. When the product is a hardware that may sound good, because systems are mostly mechanic or physical with electronic circuits.
However, when it is a software we need to ask very important questions. Engineering is not a social science. When someone says “reliable”, an engineer should ask how reliable. And he must be expecting some numbers to explain the probability of a failure within a certain time period.
Well, software reliability suggests some models to answer these questions. Let’s have a look the current practices and some handy formulas which may be useful for practitioners.
Some definitions and formulas of Conventional Theory about reliability:
The following definitions and formulas are good for a basic understanding. However, the practitioners should refer to the reliability models I provide in the following section.
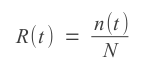
N is the number of identical components and n(t) is the number components functioning correctly.
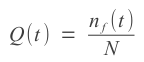
N is the number of identical components and nf(t) is the number components functioning incorrectly.
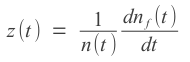
first failure occurs.
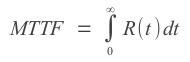
Any given system will have only a 37% chance of functioning correctly for an amount of time equal to the MTTF and naturally 63% chance of not functioning correctly for the same period.
MTBF = MTTF + MTTR
Current State of the Practice of Software Reliability
Having a mature software reliability requires the experts to deal with an immature area: software testing. One of the crucial concepts is automated testing. Using automated testing 1 million test cases may be generated and applied to the software.
Moreover, the test cases rely on sound statistical principles which make them fresh test suites.
It is also obvious that there is an effort to standardize the metrics used for software reliability. This is a crucial improvement considering that Reliability Models must be evaluated using the same reliability metrics.
As the complexity of the software platforms increases it is not always possible to test the software and determine reliability parameters on all platforms. In this case automated system reporting has become a useful practice.
The software development for ultra-reliable systems are leading the improvements in software reliability as
expected. Because these developers are under a great pressure of creating failure-free systems considering that one failure usually yields catastrophic results in such industries.
Moreover, having a look at the methods adopted by ultra-reliable system designers we can perceive the deterministic measures to deploy the software.
What are the models used for evaluating the reliability of a software?
Basically, these models are based on the data gathered while testing the software system. In AGILE approach, there is no distinct testing phase as in Waterfall/Spiral . However, it is still possible to generate some useful data about bugs found during the different phases of AGILE methodology thanks to the systematic software tools used for monitoring the progress.
SR (Software Reliability) Models are classified in two groups:
Reliability Growth Models are found to be promising and preferred by the majority of software reliability practitioners. The most popular SRGM models:
Basic Execution Time (BET) Model:
Dr. Musa indicated the importance of using execution time rather than raw time for the testing/debugging period. This model also includes refinements to the previous NHPP Model.
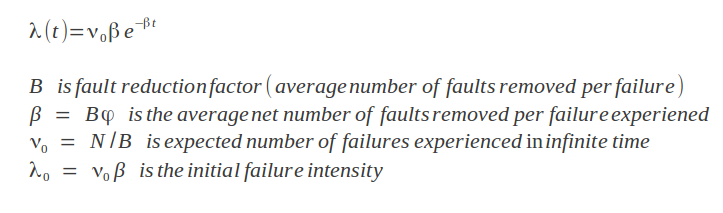
I have implemented the following functions to calculate the failure rate or the time needed to achieve a desired failure rate.
BET failure rate:
|
1 2 3 |
betLFromT <- function(t, k, No) { k*No*exp(-k*t) } |
Calculating the total testing time needed to achieve a failure rate:
|
1 2 3 |
betTFromL <- function(L, k, No) { log(k*No/L)/k } |
Logarithmic Poisson Model:
This model is an NHPP with an exponentially decreasing failure function where “theta” is the failure intensity decay parameter.
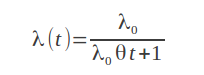
Similarly, the following functions will be useful for calculating necessary values.
Calculating failure rate:
|
1 2 3 |
lPoisLfromT <- function(t, lo, tha) { lo/(lo*tha*t+1) } |
And calculating the needed execution time:
|
1 2 3 |
lPoisTfromL <- function(L, lo, tha) { (lo/L-1)/(lo*tha) } |
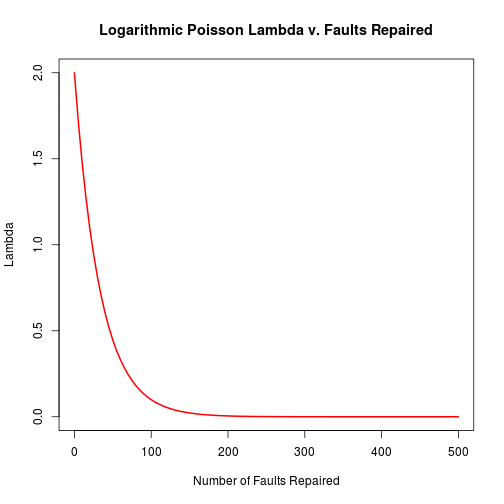
Following is the implementation for calculating failure rate from number of faults repaired.
|
1 2 3 |
lPoisLfromNc <- function(nc, lo, tha) { lo*exp(-tha*nc) } |
How can we find the parameters used in the formulas?
Well, we have some unknown parameters such as theta, beta, nu, etc. We do not know these for sure. Each software development/testing team will have different parameters. Even an experienced programmer may impact these parameters greatly. The engineer/manager responsible for reliability should collect some data from previous projects and use a regression model to estimate these models.
A transformation to make life better:
BET Model ![]() can be transformed into:
can be transformed into:

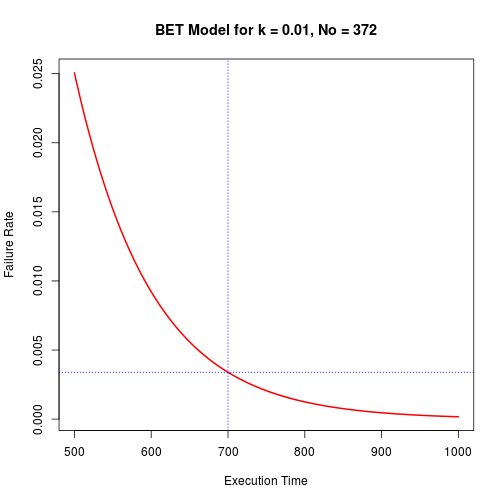
Now collect the data as log of failure rate (in terms of number of bugs) and time, Calculate intercept and beta1. Your reliability growth model (BET) is ready. You will be able draw graphs like this:
Recent Comments